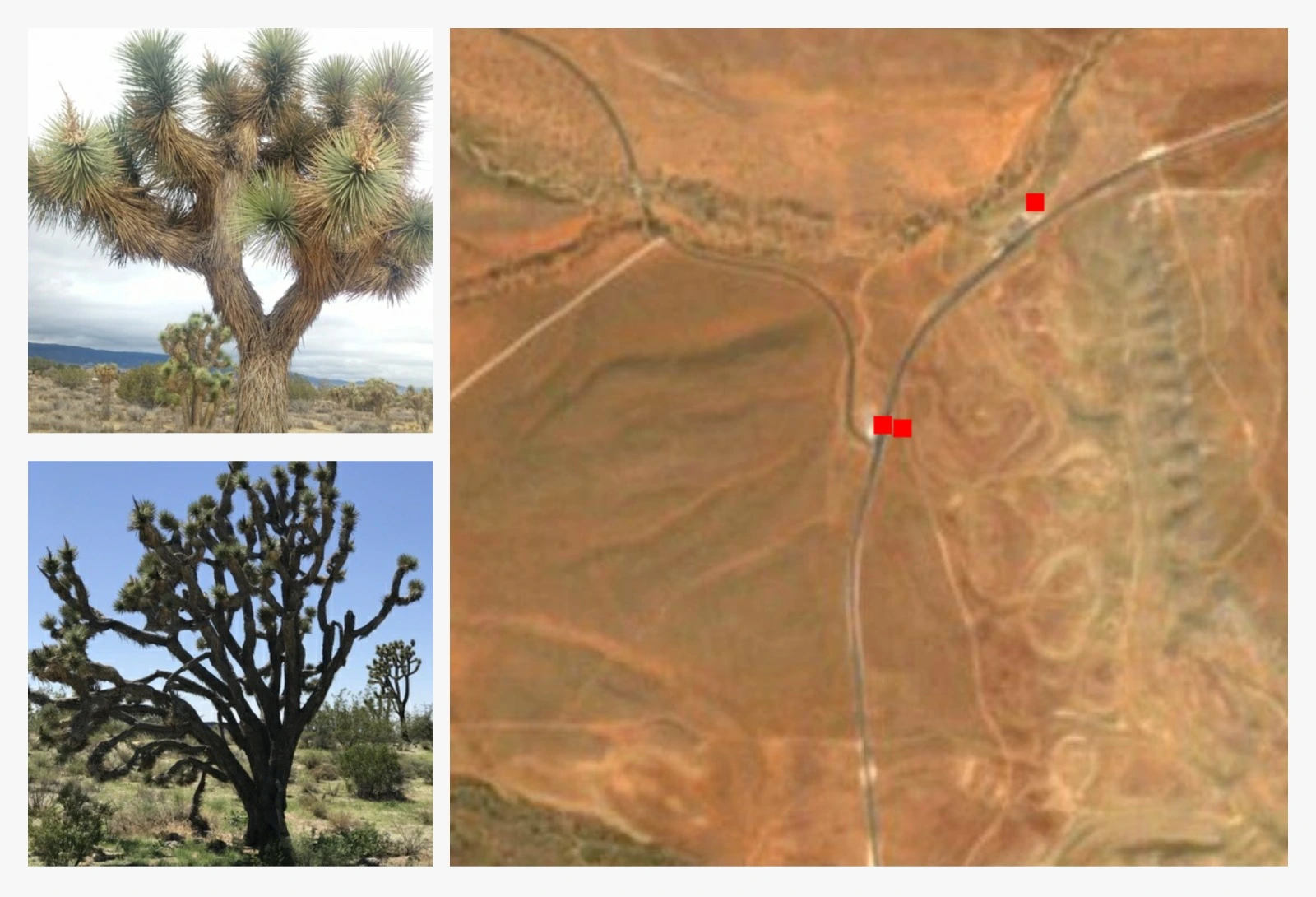
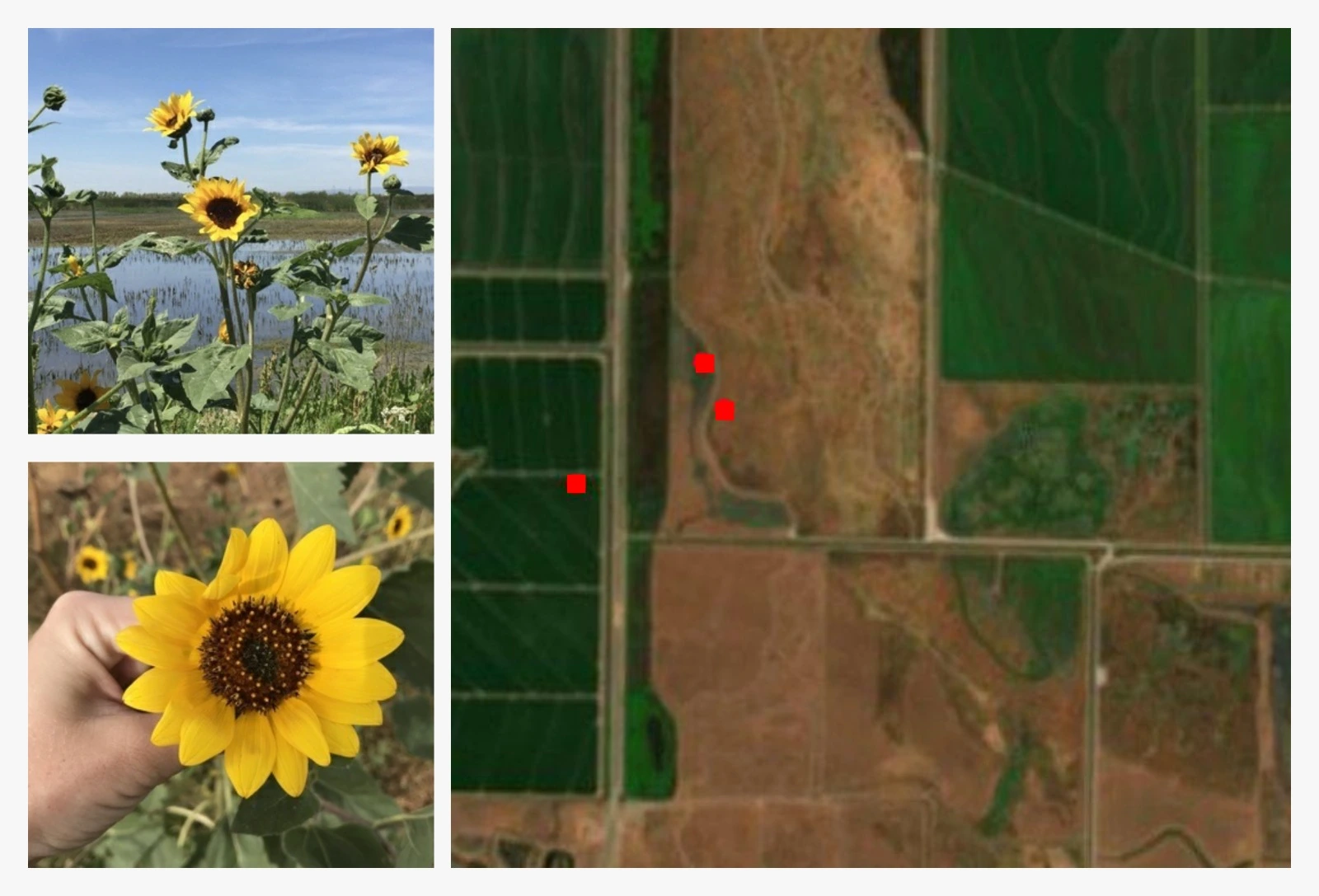
To perform outdoor visual navigation and search, a robot may leverage satellite imagery to generate visual priors.
This can help inform high-level search strategies, even when such images lack sufficient resolution for target recognition.
However, many existing informative path planning or search-based approaches either assume no prior information, or use priors without accounting for their origins.
Recent work instead utilizes large Vision Language Models (VLMs) for generalizable priors, but their outputs can be inaccurate due to hallucination, leading to inefficient search.
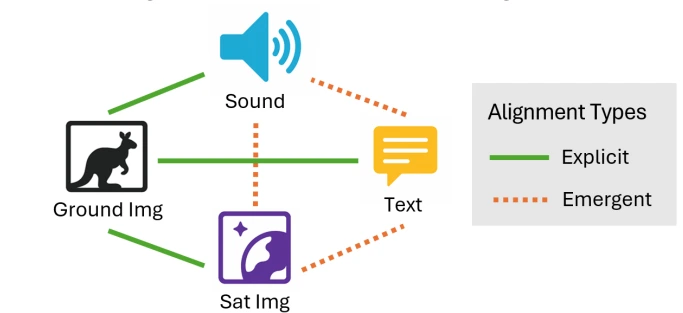
To address these challenges, we introduce Search-TTA, a multimodal test-time adaptation framework with a flexible plug-and-play interface compatible with various input modalities (e.g., image, text, sound) and planning methods (e.g., RL-based).
First, we pretrain a satellite image encoder to align with CLIP’s visual encoder to output probability distributions of target presence used for visual search.
Second, our TTA framework dynamically refines CLIP’s predictions using uncertainty-weighted gradient updates online during search.
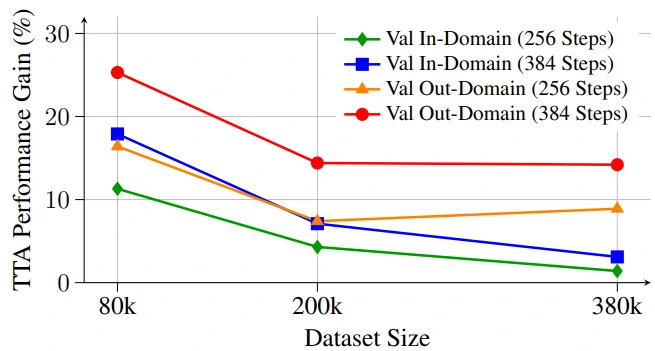
To train and evaluate Search-TTA, we curate AVS-Bench, a visual search dataset based on internet-scale ecological data containing 380k images and taxonomy data.
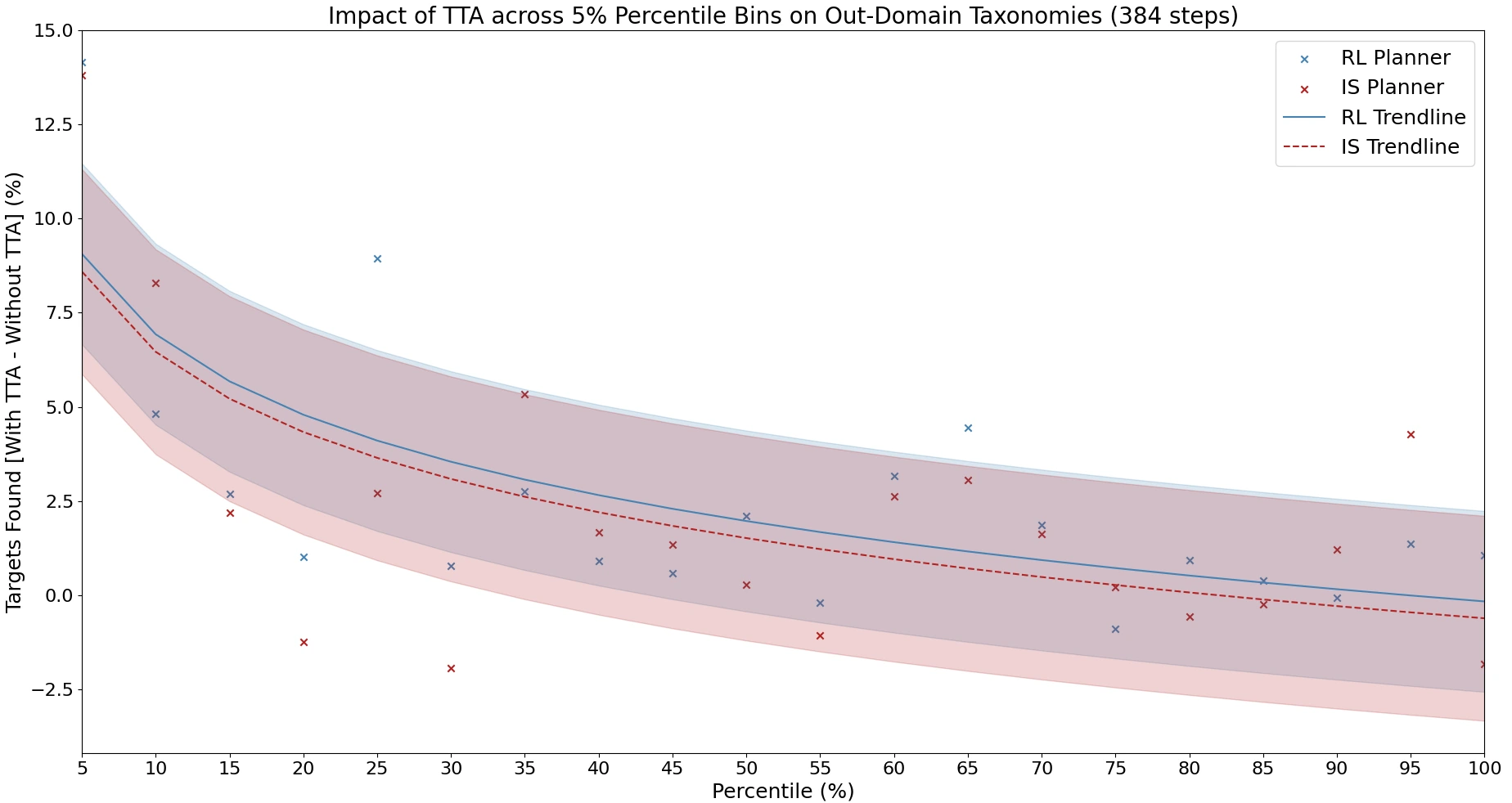
We find that Search-TTA improves planner performance by up to 30.0%, particularly in cases with poor initial CLIP predictions due to domain mismatch and limited training data.
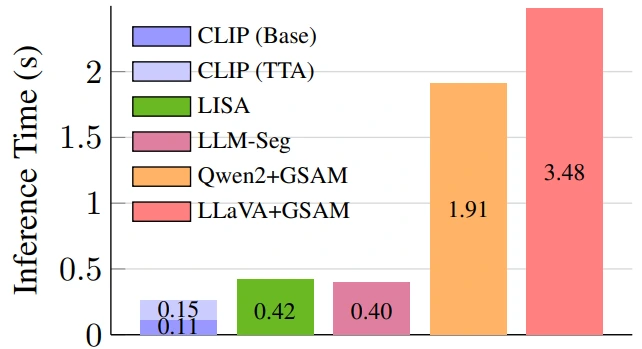
It also performs comparably with significantly larger VLMs, and achieves zero-shot generalization via emergent alignment to unseen modalities.